March 30, 2026
In this article we will explain everything you need to know about the “Discovered Not Currently Indexed” status and how you can resolve it.
Firstly, let’s cover what this status is and what it means. Discovered Not Currently Indexed is one of many exclusion types. Google Search Console provides information on a variety of different exclusion types.
In short, when a page has the status “Discovered – Not Currently Indexed” Google has crawled the page, however at this time has chosen not to index the page. There are a number of reasons that can cause this.
Google gives a full explanation of the issue as follows:
“Discovered – currently not indexed: The page was found by Google, but not crawled yet. Typically, Google wanted to crawl the URL but this was expected to overload the site; therefore Google rescheduled the crawl. This is why the last crawl date is empty on the report.”
To find affected pages, first log into the sites Google Search Console account. Navigate to excluded to see the affected pages.
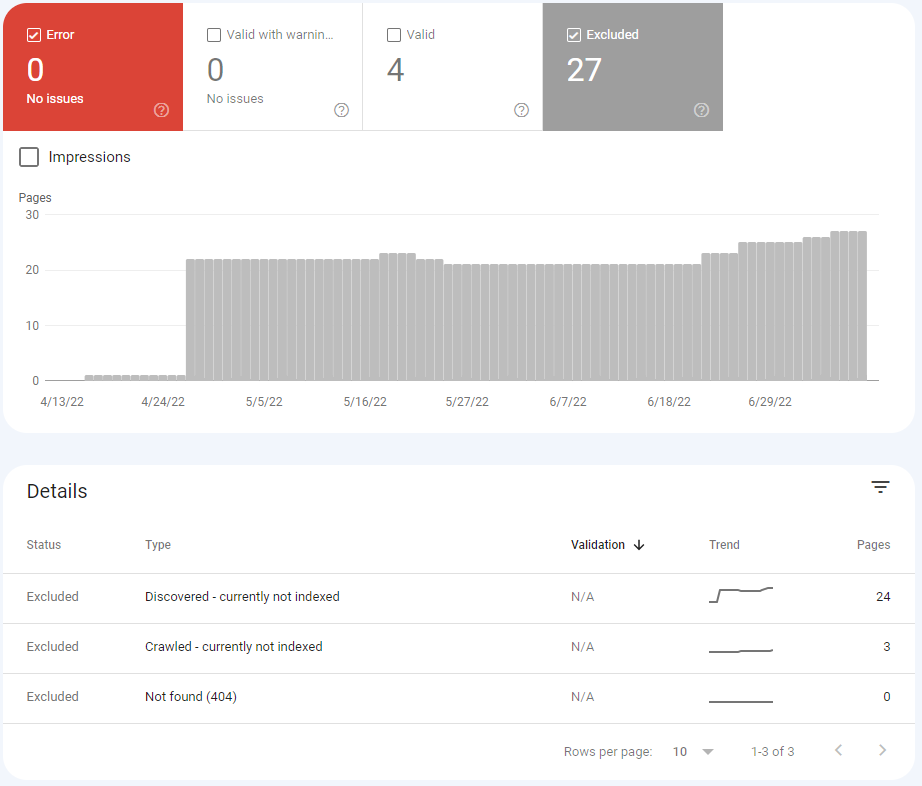
There are 24 pages currently suffering from the issues in the above example.
How To Solve Discovered Currently Not Indexed Pages:
Google has a minimum expectation of website content. Website content must achieve a high level of quality before Google will show the page within search results. Due to this, If pages on a website have poor quality content Google will exclude them from SERPs. Poor quality pages can also affect good quality pages on the site as Google will also exclude additional pages.
It is important to ensure each page on your website has unique and where possible high quality content.
All websites will require low quality content pages. Therefore, adding low quality pages to a Robots.txt ensures Google will not attempt to crawl.
Recently, John Mueller shared the following advice:
[…] Making bigger quality changes on a website takes quite a bit of time for Google systems to pick that up. […] This is something more along the lines of several months and not several days. […] Because it takes such a while to get quality changes picked up, my recommendation would be not to make small changes and wait and see if it’s good enough, but rather really make sure that, if you’re making significant quality changes, […] it’s really good quality changes […]. You don’t want to wait a few months and then decide, ‘Oh, yeah, I actually need to change some other pages, too.’
Based on this advice we recommend to ensure that your website is as compliant as possible with Googles content standard’s and that any new content is inline with best practice.
When crawling your website Googlebots follow internal links around the site. Because of this, it is recommended important pages are linked frequently. Ensuring proper internal linking creates a logical structure around the website.
We recommend:
Google indexes are increasingly excluding new websites from search results. Google do this to ensure search results provide a high quality experience for users.
Earlier this year, John Mueller provided the below context:
That can be forever […]. And especially with a newer website, if you have a lot of content, then I would assume that it’s expected that a lot of the new content for a while will be discovered and not indexed. And then over time, usually, it kind of shifts over. And it’s like, well, it’s actually crawled or it’s actually indexed when we see that there’s actually value in focusing more on the website itself.
If (as a new website) you are experiencing exclusions we recommend to continue to post high quality content regularly. Unfortunately there isn’t a clear quick fix for this issue other than continue to prove to Google your content is worth indexing.
Crawl budget issues are the number of pages that Google will crawl on a website. Whilst typically impacting larger websites more crawl budget issues can also affect smaller sites.
Due to its size large websites are often penalised if they take a significant amount of time to be crawled. However, it is possible to avoid exclusions by ensuring that the pages that are crawled are good quality pages and that any pages that do not need to be crawled are excluded by Robots.txt.
Crawl budget issues should not affect smaller websites, however if there is an issue with the server capacity then it could become a factor. If this issue is not clear check with your hosting provider to ensure there is sufficient capacity to allow for Google to crawl the site.
To assist Google in crawling the site we also recommend having an up to date sitemap.
Hopefully this guide has provided some context on how to tackle the exclusion. Our advice is to follow the best practice guidelines provided.
Most common issues:
Follow the above guidelines as a starting point to remove exclusions.
If you still require further support in resolving index exclusions, contact our expert team.
If you have an idea in mind, feel free to reach out by submitting the form below to schedule a discovery call with us.